ConGraT
Project
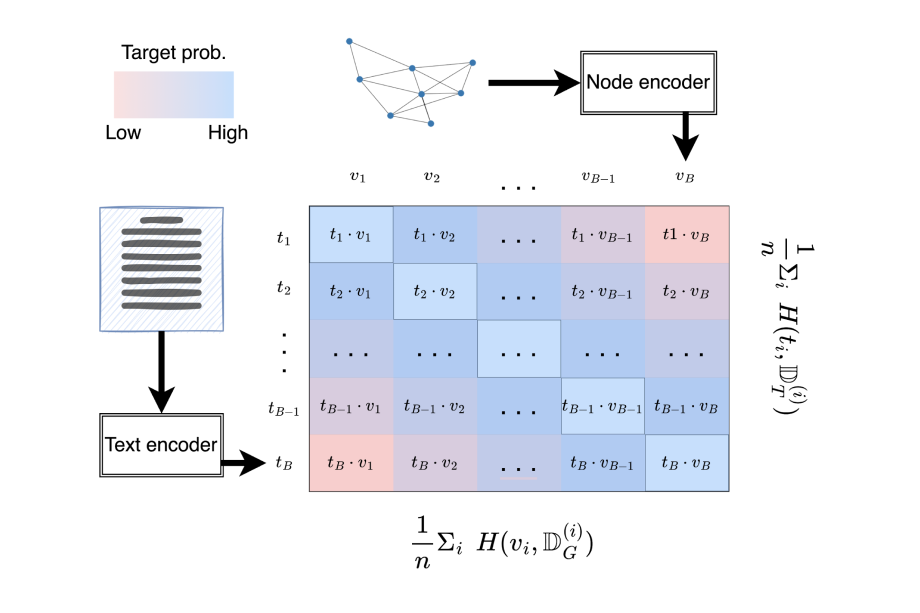
Many platforms and datasets contain text-attributed graphs, where nodes characterized by texts are connected by edges. Examples include social media users, posts and follow relationships, as well as academic articles and their citations. We've developed a method called ConGraT for jointly modeling the texts and nodes in such graphs. This method is versatile and can be used on various platforms like social media, articles, and web pages, without being tailored to any specific type or structure of data. It trains a model to align texts and the corresponding nodes within a shared embedding space, making for more efficient use of data for downstream tasks. Our experiments have shown that ConGraT performs better than existing methods in classifying and predicting links between texts and items.